



빅데이터(Big Data) 완벽 가이드: 데이터가 곧 자본이다
Big Data
빅데이터:
데이터가 곧 자본이다

PB(페타바이트)급 정보를 수집하고 분석하여 미래를 예측하다.
단순한 숫자의 나열을 비즈니스의 통찰력으로 변환하는 21세기의 원유이자 핵심 자원입니다.
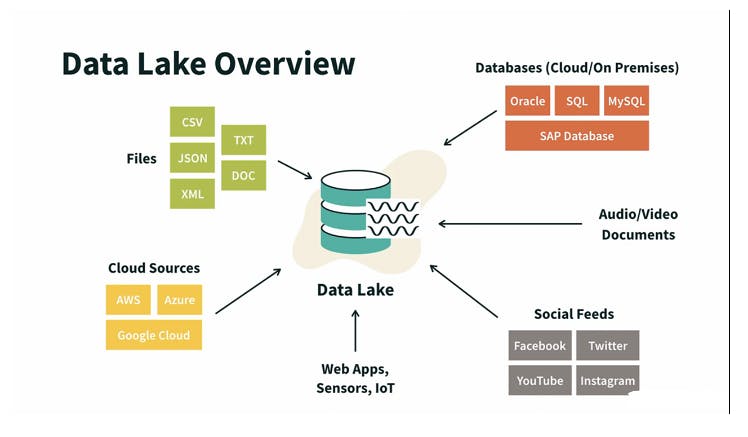
1. 빅데이터(Big Data)란? (Deep Dive)
빅데이터(Big Data)는 기존의 데이터베이스 관리 도구로는 수집, 저장, 관리, 분석할 수 없는 방대한 양의 정형 및 비정형 데이터 집합을 의미합니다. 단순히 양(Volume)만 많은 것이 아니라, 생성 속도(Velocity)가 빠르고 형태가 다양(Variety)해야 하며, 이를 분석하여 새로운 가치(Value)를 창출하는 기술적 과정을 포함합니다.
2026년형 빅데이터의 트렌드는 '데이터 패브릭(Data Fabric)'과 '실시간 분석(Real-time Analytics)'입니다. 물리적으로 흩어진 데이터를 가상화하여 하나의 플랫폼처럼 연결하고, 생성되는 즉시 분석하여 0.1초 만에 비즈니스 액션으로 연결하는 초연결·초고속 지능형 시스템이 표준이 되고 있습니다.
비즈니스 판도를 바꾸는 3대 핵심 가치
1. 데이터 기반 의사결정 (Data-Driven)
경영진의 직관이나 과거의 제한적인 경험에 의존하던 의사결정 방식을 탈피합니다. 수집된 대규모 데이터를 통계적으로 분석하고 시뮬레이션함으로써, 불확실성을 제거하고 성공 확률이 가장 높은 선택지를 도출하는 과학적인 경영 기법을 완성합니다.
2. 초개인화 서비스 (Hyper-Personalization)
고객의 구매 이력뿐만 아니라 행동 패턴, 체류 시간, 검색어까지 분석하여 '나보다 나를 더 잘 아는' 추천을 제공합니다. 넷플릭스나 유튜브처럼 개별 사용자에게 완벽하게 맞춤화된 콘텐츠와 상품을 제안하여 고객 충성도를 극대화합니다.
3. 미래 예측 및 최적화 (Predictive Analysis)
과거의 데이터를 학습하여 미래의 수요를 예측하고 설비 고장을 미리 감지합니다. 제조 공장의 예지 보전부터 유통업의 재고 최적화까지, 일어날 일을 미리 파악하고 선제적으로 대응하여 비용을 줄이고 운영 효율을 혁신합니다.
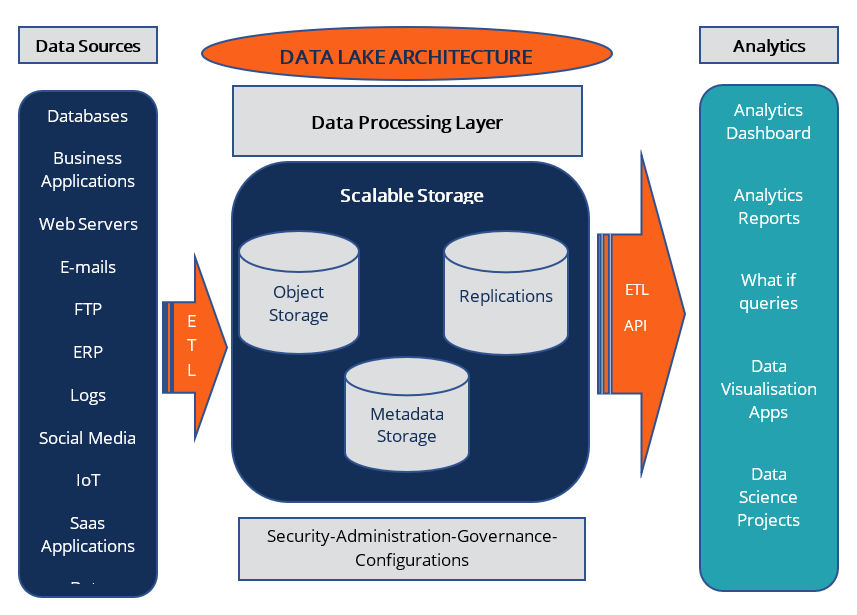
2. 기술 심층 분석: 처리 인프라 비교
데이터의 규모와 처리 목적에 따라 온프레미스, 클라우드, 하이브리드 중 최적의 아키텍처를 선택해야 합니다.
1. 온프레미스 하둡 (On-Premise Hadoop)
기업 내부 서버에 하둡(Hadoop) 클러스터를 직접 구축하여 대용량 데이터를 분산 처리하는 방식입니다. 보안성이 뛰어나고 초기 구축 후 데이터 처리 비용이 저렴하지만, 유연한 확장이 어렵고 전문 엔지니어의 지속적인 유지보수가 필요합니다.
2. 클라우드 데이터 레이크 (Cloud Data Lake)
AWS, Azure 등 클라우드 스토리지에 데이터를 저장하고 필요할 때만 컴퓨팅 자원을 빌려 씁니다. 초기 투자비가 없고 데이터 양에 따라 무한 확장이 가능하며, 최신 AI 분석 도구를 즉시 활용할 수 있어 가장 빠르게 성장하는 모델입니다.
3. 인메모리 처리 (In-Memory Processing)
디스크가 아닌 메모리(RAM)상에서 데이터를 처리하는 Spark 같은 기술을 활용합니다. 기존 디스크 기반 처리보다 100배 이상 속도가 빨라 실시간 금융 거래 분석이나 실시간 광고 입찰 등 초고속 처리가 필요한 영역에 필수적입니다.
| 구분 | 온프레미스 (Hadoop) | 클라우드 (Cloud) | 하이브리드 (Hybrid) |
|---|---|---|---|
| 초기 비용 | 매우 높음 (서버 구매) | 낮음 (사용량 과금) | 중간 |
| 확장성 (Scale) | 낮음 (물리적 증설 필요) | 최상 (무한 확장 가능) | 우수 |
| 보안/통제권 | 최상 (내부망 폐쇄) | 중간 (CSP 책임 공유) | 우수 (중요 데이터 내부) |
| 주요 용도 | 금융, 공공 등 보안 필수 | 스타트업, 글로벌 서비스 | 대기업, 민감 정보 보호 |
3. ROI 분석: 데이터 투자의 경제성
빅데이터는 단순한 저장 비용이 아니라, 새로운 비즈니스 기회를 창출하는 고수익 투자 자산입니다.
1. 운영 비용 획기적 절감 (Cost Saving)
운영비 20% 절감공급망 데이터를 분석하여 재고 회전율을 높이고 물류 이동 경로를 최적화합니다. 불필요한 재고 보관 비용과 운송비를 줄이고, 에너지 소비 패턴을 분석하여 공장이나 빌딩의 에너지 비용을 획기적으로 낮출 수 있습니다.
2. 신규 수익 모델 창출 (Monetization)
매출 15% 증대축적된 데이터를 가공하여 타사에 판매하거나, 데이터 분석 결과를 기반으로 한 컨설팅 서비스를 제공합니다. 기존 제품 판매를 넘어 데이터 자체를 상품화하거나, 데이터 통찰력을 통해 완전히 새로운 시장 기회를 발굴합니다.
3. 리스크 관리 및 사기 방지 (Risk Management)
손실액 90% 방어금융 거래 패턴을 실시간 분석하여 이상 징후(Fraud)를 탐지하거나, 설비의 고장 전조 증상을 포착합니다. 사기 대출이나 보험 사기를 사전에 차단하고, 돌발적인 설비 고장으로 인한 생산 중단 손실을 원천적으로 막습니다.
4. 도입 예산 가이드: 규모별 비용 (Budgeting)
데이터의 양(Volume)과 분석의 깊이, 그리고 사용할 솔루션(SaaS/구축형)에 따라 예산이 결정됩니다.
1. 소규모 분석/BI 도입 (Entry)
연 2,000만 원 ~ 5,000만 원데이터 웨어하우스(DW) 없이 Tableau나 PowerBI 같은 시각화 도구를 도입하여 엑셀 데이터를 분석하는 단계입니다. 클라우드 SaaS 형태로 시작하여 초기 구축비가 거의 들지 않으며, 팀 단위의 데이터 분석에 적합합니다.
2. 중형 데이터 레이크 구축 (Standard)
2억 원 ~ 5억 원전사적인 데이터를 통합 저장하는 데이터 레이크를 구축하고, ETL(추출/변환/적재) 파이프라인을 개발하는 단계입니다. 전문 데이터 엔지니어 채용 비용과 클라우드 스토리지 비용, 분석 플랫폼 라이선스 비용이 포함됩니다.
3. 대형 AI/ML 플랫폼 구축 (Enterprise)
10억 원 ~ 수십억 원실시간 스트리밍 데이터 처리와 자체 AI 모델 개발을 위한 고성능 GPU 클러스터 및 MLOps 환경을 구축합니다. 데이터 사이언티스트 전담 조직 운영비와 대규모 인프라 유지보수 비용이 지속적으로 투입됩니다.
5. Industry 4.0: 스마트 분석 기술
데이터 분석의 주체가 사람에서 AI로 넘어갔습니다. 스스로 학습하고 인사이트를 도출하는 자동화의 시대입니다.
1. AutoML (자동화된 머신러닝)
분석 시간 90% 단축데이터 전처리부터 모델 선택, 파라미터 튜닝까지 복잡한 머신러닝 과정을 AI가 자동으로 수행합니다. 전문 지식이 부족한 비즈니스 분석가도 클릭 몇 번으로 고성능 예측 모델을 만들고 활용할 수 있게 합니다.
2. 데이터 가상화 (Data Virtualization)
데이터 통합 비용 50% 절감물리적으로 데이터를 한곳에 모으지 않고, 가상 계층에서 여러 소스의 데이터를 연결하여 보여줍니다. 복잡한 ETL 과정 없이 실시간으로 데이터를 조회할 수 있어 데이터 사일로(Silo) 문제를 가장 효율적으로 해결합니다.
3. 실시간 스트리밍 분석
지연 시간 0.1초 미만Kafka나 Flink 같은 기술을 이용해 데이터를 저장하기 전에 흐르는 상태에서 즉시 분석합니다. 금융 사기 탐지나 스마트 팩토리의 이상 감지처럼 1초의 지연도 허용되지 않는 미션 크리티컬한 업무에 적용됩니다.
6. 유지보수(PM): 데이터 거버넌스
쓰레기 데이터(Garbage)가 들어가면 쓰레기 결과가 나옵니다. 데이터 품질과 보안 관리가 시스템의 핵심입니다.
| 관리 포인트 | 핵심 점검 항목 (Check Point) |
|---|---|
| 데이터 품질 (Quality) | 결측치, 중복, 형식 오류를 주기적으로 점검. 정제되지 않은 데이터는 분석 결과의 신뢰도를 떨어뜨림. |
| 메타데이터 관리 | 데이터의 출처, 생성일, 의미를 정의한 데이터 사전을 최신화. 누가 어떤 데이터를 쓰는지 파악 가능. |
| 접근 제어 및 감사 | 민감 정보에 대한 접근 권한을 최소화하고, 누가 언제 어떤 데이터를 조회했는지 로그를 남겨 보안 사고 예방. |
7. 실무 FAQ: 데이터 담당자의 핵심 질문
개인정보 이슈, 비정형 데이터 처리, 클라우드 비용 등 현장에서 가장 많이 부딪히는 문제들입니다.
Q. 고객 데이터를 분석해도 법적 문제가 없나요?
A. 개인정보보호법에 따라 식별 가능한 정보는 반드시 가명 처리 또는 익명 처리를 해야 합니다. 분석 목적이라도 고객의 명시적 동의 없이는 원본 데이터를 사용할 수 없으므로 철저한 비식별화 조치가 선행되어야 합니다.
Q. 텍스트나 이미지 같은 비정형 데이터는 어떻게 하나요?
A. 기존 DB에는 저장이 어렵기 때문에 오브젝트 스토리지(S3 등)에 저장하고, NLP(자연어 처리)나 비전 AI 기술로 분석 가능한 형태로 변환합니다. 전체 데이터의 80%가 비정형 데이터인 만큼 이를 활용하는 것이 핵심입니다.
Q. 클라우드 비용이 예상보다 너무 많이 나옵니다.
A. 사용하지 않는 인스턴스를 끄지 않거나, 비효율적인 쿼리를 날려서 발생하는 경우가 많습니다. FinOps(핀옵스)를 도입하여 실시간으로 비용을 모니터링하고, 데이터 수명 주기에 따라 저렴한 스토리지로 옮기는 정책이 필요합니다.
8. 산업별 성공 도입 사례 (Case Study)
데이터를 통해 비효율을 걷어내고 새로운 가치를 찾아낸 기업들의 혁신 사례입니다.
기상청 날씨 데이터와 인근 지역 축제 정보를 POS 데이터와 결합하여 점포별 발주량을 AI가 추천했습니다. 폐기율을 30% 줄이고, 행사 당일 맥주와 도시락 매출을 2배 이상 끌어올리는 성과를 거두었습니다.
수십 년 경력의 장인에게 의존하던 용광로 온도 조절을 센서 데이터 기반의 AI 모델로 대체했습니다. 1도 단위의 정밀한 온도 제어가 가능해져 연료비를 연간 5% 절감하고 품질 편차를 획기적으로 줄였습니다.
고객의 결제 위치와 시간을 실시간으로 분석하여, 결제 직후 근처 카페나 맛집의 할인 쿠폰을 앱 푸시로 발송했습니다. 스팸성 문자가 아닌 맞춤형 혜택으로 인식되어 쿠폰 반응률이 기존 대비 4배 상승했습니다.
9. 도입 후 트러블 사례와 사전 대책 (Troubleshooting)
데이터 프로젝트 실패의 원인은 대부분 기술이 아니라 데이터 품질과 조직 문화에 있습니다.
| 장애 현상 (Symptom) | 원인 분석 (Cause) | 해결 (Solution) |
|---|---|---|
| 분석 결과 불신 | 입력 데이터 품질 저하 (Garbage In, Garbage Out) | 데이터 전처리 프로세스 강화 및 품질 지표(KPI) 관리 도입 |
| 데이터 사일로 (Silo) | 부서 간 데이터 공유 거부 및 시스템 단절 | 전사적 데이터 거버넌스 수립 및 CDO(최고 데이터 책임자) 임명 |
| 쿼리 속도 저하 | 비효율적인 SQL 작성 및 인덱스 누락 | DB 튜닝 전문가 투입 및 자주 쓰는 데이터의 마트(Mart) 구성 |
데이터는 21세기의 원유.
하지만 정제하지 않으면 가치가 없습니다.
2026년형 빅데이터 분석 솔루션으로 잠들어 있는 데이터에서 황금 같은 인사이트를 캐내십시오.


